
Qwen3.6-Plus is Alibaba Cloud’s latest balanced flagship model in Model Studio, arriving shortly after ロイター reported that Qwen leader Junyang Lin had stepped down. Alibaba Cloud’s current documentation lists a 1,000,000-token context window, default-on mixed reasoning mode, multimodal input, and pricing that starts at 2 RMB per million input tokens in Mainland China for requests up to 256K input tokens.
Qwen3.6-Plus Features and Benchmarks
Long context, pricing, and reasoning mode
Alibaba Cloud positions Qwen3.6-Plus as a flagship model that balances quality, speed, and cost. In the official model docs, the stable version is listed with a 1,000,000-token context window, up to 65,536 output tokens, and a maximum thought length of 81,920 tokens in thinking mode; the same docs also show that thinking mode is enabled by default.
The same documentation shows that Qwen3.6-Plus supports text, image, and video input, which matters because it moves the model beyond pure text generation into multimodal analysis. That makes it more relevant for workflows such as GUI understanding, document parsing, and mixed-media reasoning, not just standard chat or code completion.
Coding and multimodal positioning
Alibaba’s product docs describe Qwen3.6-Plus as strong across language understanding, logical reasoning, code generation, agent tasks, image understanding, video understanding, and GUI tasks. The official Qwen launch page also frames the model as improving coding agents, general agents, and tool use through tighter integration of reasoning, memory, and tool interaction.
That positioning suggests a model aimed at practical execution rather than simple prompt-response demos. In editorial terms, it is fairer to describe Qwen3.6-Plus as a hosted coding and agent model than as a general-purpose chatbot with a coding mode added on top.
How to read the benchmark results
Alibaba’s launch materials report vendor-published results that include 78.8 on SWE-bench Verified and 61.6 on Terminal-Bench 2.0. The same launch materials also highlight gains on broader real-world agent and multimodal evaluations, so the company is clearly presenting Qwen3.6-Plus as a model optimized for execution-heavy workflows rather than narrow single-turn tasks.
Some users have also questioned the choice of comparison targets, asking why Qwen3.6-Plus was not benchmarked directly against クロード・オプス 4.6 または ジェミニ 3.1 プロ. A more likely explanation is product positioning. Qwen3.6-Plus belongs to the Plus series, which is designed for high-concurrency usage, so its comparison set is closer to models such as Claude 4.5 Opus in terms of deployment scenarios and compute-consumption level. From that perspective, the selected benchmarks appear to reflect practical product alignment rather than simply aiming at the newest model names.
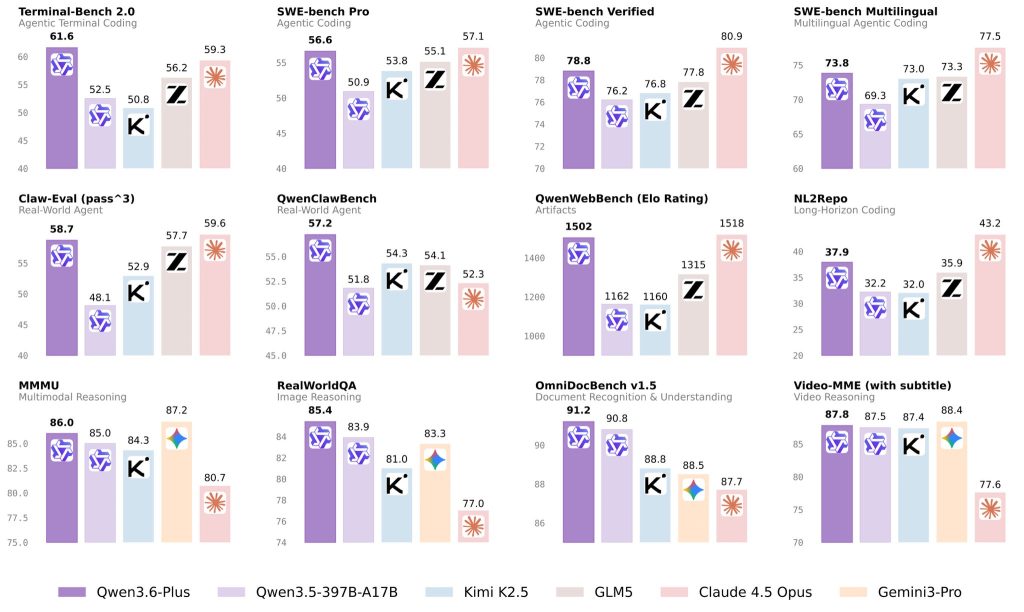
Those numbers are more useful when paired with the original benchmark definitions. SWE-bench evaluates whether a model or agent can resolve real GitHub issues inside actual repositories; SWE-bench Verified is a 500-task human-filtered subset; Terminal-Bench 2.0 measures performance on 89 hard terminal tasks inspired by real workflows; and OmniDocBench evaluates diverse PDF parsing across nine document sources with fine-grained layout and attribute annotations.
| ベンチマーク | What it measures | Why it matters |
| SWEベンチ検証済み | Real software issue resolution in codebases | Useful for judging repository-level debugging and patch generation |
| ターミナルベンチ 2.0 | Multi-step command-line task execution | Useful for terminal automation, setup flows, and agent reliability |
| OmniDocBench | Complex PDF and document parsing | Useful for technical papers, specifications, tables, and formulas |
| Real-world agent evals | Multi-step planning and tool use | Useful for end-to-end workflow completion rather than isolated answers |
A practical example is a long-context engineering task where the model must read a large repository, identify the relevant files, plan a fix, execute terminal actions, and verify the result. Another is parsing long technical PDFs or image-heavy documents before converting them into summaries, implementation notes, or downstream tasks.
What Is the Discussion Around Qwen3.6-Plus
The timing of this release matters because it arrived shortly after the reported leadership change within the Qwen team. That context does not by itself prove a strategic break, but it does help explain why the launch has drawn attention beyond model specifications alone. In practice, many readers are evaluating both the product itself and what it may signal about Qwen’s next phase.
While reviewing developer discussions across technical communities, I noticed that the main focus was not entirely on benchmark scores. Instead, much of the attention centered on the fact that Qwen3.6-Plus is currently released in a hosted, closed-source form, with access limited to API calls and platform preview.
That reaction is understandable. Earlier Qwen releases built significant goodwill among developers through a more open approach, so this rollout has triggered discussion about what the shift may mean in practice.
The first concern is local deployment and data privacy. Many enterprise users rely on open models for on-premise fine-tuning and private deployment in order to meet strict compliance and security requirements. A closed, API-based model means that codebases, documents, or business data may need to be processed through the cloud, which can make adoption more difficult in privacy-sensitive sectors such as finance and healthcare.
The second concern is the pace of ecosystem and toolchain adaptation. Open models tend to generate community plugins, quantized variants, fine-tuning workflows, and third-party utilities very quickly. If the core Qwen3.6 line remains closed, some developers may be less willing to invest in building external tools and integrations around it.
A third interpretation is more commercial than technical. Some industry observers see this as a possible signal of Alibaba Cloud’s broader monetization strategy: keeping its most capable models inside its own cloud platform in order to strengthen managed-service adoption, API usage, and related compute revenue.
Overall, this does not necessarily weaken the product itself. However, it does change the trade-offs. For teams already operating inside Alibaba Cloud, the hosted model may be convenient and cost-effective. For teams that prioritize self-hosting, governance, or deep customization, the deployment model may matter almost as much as the benchmark results.
Qwen3.6-Plus looks like a serious hosted option for developers who care about long context, coding workflows, and multimodal agent tasks. Its official spec sheet is strong, its pricing is relatively aggressive at the low end, and Alibaba’s launch materials position it credibly in execution-heavy benchmark categories, but the hosted rollout may still be a meaningful consideration for teams that prefer open-weight or self-hosted models.


