
私はGLM-5を主に エンジニアリングモデル単に「正しく聞こえる」だけでよい一般的なチャットモデルとしてではなく、私のアプローチは単純です。まず、広く参照されている公開ベンチマークを使用して、GLM-5がトップ層に位置付けられていることを確認します。次に、それらの信号を検証します。 繰り返し可能なワークフロー GLM-5が実際のエンジニアリングタスクにおいて本当に安定し、実用的であるかどうかを検証しました。このプロセスに基づいて、GLM-5の進歩は規模だけでなく、 長期コンテキスト効率, エージェントトレーニング、 そして エンジニアリンググレードの出力安定性 同時に。この組み合わせは、複合リーダーボードと現実世界のエージェント評価の両方で、主要なクローズドモデルに近いパフォーマンスを発揮する理由を説明するのに役立ちます。
GLM-5の位置づけを確立するために2つの指標を使用する
主観的な印象だけに頼らないようにするために、私は GLM-5 の評価を 2 つの補完的な人工分析評価トラックに結び付けます。
- 人工知能分析指数 (複合能力スコア): GLM-5スコア 50で、トップクラスに位置します。より高いスコアには、Claude Opus 4.6(適応推論)があります。 53 GPT-5.2(xhigh)では 51クロード・オプス4.5も 50 範囲。この指標は、複数の評価を単一のスコアに集約し、推論、コーディング、および関連能力の総合的な強さを反映します。
- GDP値-AA (現実世界の知識労働のエージェント評価): GLM-5は Eloレーティング1412簡単に言えば、Eloは 直接対決の相対的な強さスコア—Eloが高いほど、同じタスクセットにおける全体的な勝率が高くなります。GDPval-AAは、実際の作業(例:情報の取得、分析、成果物の作成)を模倣するように設計されており、ツールにアクセスできるエージェントハーネス内でモデルを動作させることができます。
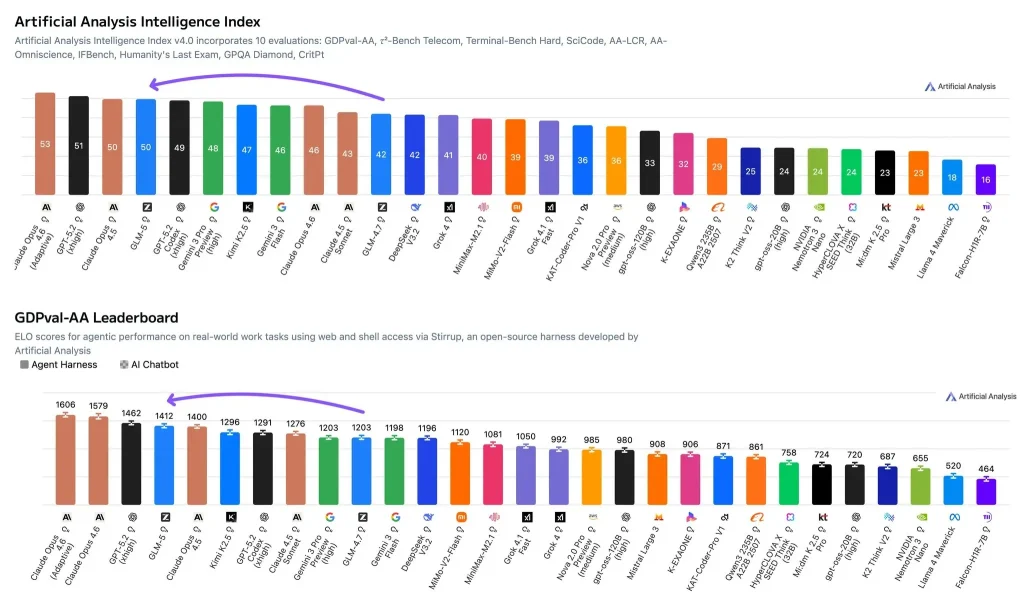
これら 2 つの指標を総合すると、明確な仮説が浮かび上がります。 GLM-5の優位性は、単独の「テストセットトリック」から生まれる可能性は低いでしょう。むしろ、複雑で複数ステップのタスクにおける完了品質と安定性から生まれる可能性が高いでしょう。
GLM-5のテスト方法:3つの高周波エンジニアリングワークフロー
私の実践的なテストは、「プロンプトショーケース」というよりは、エンジニアリングの受入れ検査に近いものです。モデルがより長い説明を生成できるかどうかよりも、制約下で正確かつ実用的な結果を生成できるかどうかに重点を置いています。主に以下の3種類のワークフローをテストしています。
- 長期コンテキストのソフトウェア エンジニアリング タスク: より長いコード セグメントとドキュメントの制約を提供し、ファイル間の問題のローカライズと最小限の変更の修正提案を要求します。
- 増分コード編集: 構造の残りの部分はそのままにして、特定の関数またはモジュールに限定した変更を要求し、diff スタイルのパッチと回帰リスクを求めます。
- ツール中心のタスク チェーン: タスクを取得 → 合成 → 成果物の作成と構造化し、モデルが不足している入力を明確に要求できるかどうか、また何かが失敗した場合に信頼できる再試行パスを提案できるかどうかを確認します。
これらのワークフローを使用するのは、知能指数とGDPval-AAの改善が最も明確に現れるはずだからです。 長いチェーン、ツールの使用、エンジニアリング成果物 短い一回限りのプロンプトではなく。
GLM-5の核となるブレークスルー:3つの強化された変更による構造的アップグレード
DSAスパースアテンションは長いコンテキストを経済的に持続可能にする
公開資料や 紙GLM-5では、 DSA(ディープシーク スパース アテンション)簡単に言えば、入力が非常に長くなると、モデルはすべてのトークンに均等な注意計算を費やす必要がなくなります。代わりに、より重要で関連性の高いトークンに多くの計算を割り当てることで、長いコンテキストの品質を維持しながら、トレーニングと推論のコストを削減します。
私のテストでは、実際の意味合いはその設計目標と一致しています。コンテキストが大きくなるにつれて、 レイテンシはよりスムーズに増加する傾向がある、 そして 出力の一貫性はより安定する傾向があるコードベースの探索、要件の蓄積、長期的な実行によって、時間の経過とともにコンテキストが自然に拡張されるため、これはエンジニアリングの設定において重要です。
非同期RLインフラストラクチャ(「スライム」)は長期的なインタラクションに適している
GLM-5は、スループットと効率性を向上させるために、軌道生成(ロールアウト)と学習を分離する非同期強化学習のセットアップを公開しています。これを実際的に解釈すると、モデルは大量のインタラクショントレースからより効果的に学習できるということです。 タスクをエンドツーエンドで完了する方法単独でもっともらしい答えを出すことだけを学ぶのではなく、
実際のワークフローでは、失敗の処理で最も明確にこのことがわかります。非生産的なテキストをループする代わりに、GLM-5は制約に戻って提案することが多くなります。 新しい実行可能なステップどの入力が欠落しているかがより明確になります。
トレーニングの目標は、単一ポイントのスキル向上ではなく、エージェントエンジニアリングへと移行
GLM-5は、「プロンプト駆動型コーディング」から エージェントエンジニアリング私はこれを、コードを書いたり、個別の推論問題を解決したりする以上のトレーニング目標であると解釈しています。モデルは、より長い期間にわたって計画、実行、および反映し、エンジニアリング ワークフローで使用できる結果を生成する必要があります。
この枠組みは、GLM-5 が GDPval-AA (知識労働エージェントタスク) で優れていると同時に、複合知能指数でも競争力のあるスコアを獲得できる理由を説明するのに役立ちます。
GLM-5が依然としてクローズドフラッグシップに「わずかに遅れをとる」理由:差は縮まったものの、ゼロではない
GLM-5はすでに同じトップレベルのスコアバンドに入っています
あ 50 知能指数(Intelligence Index)のスコアは、総合評価において大きな弱点がないことを示唆しています。そうでなければ、このレベルのスコアを維持することは困難でしょう。Claude Opus 4.5と同等のバンドに位置し、Claude Opus 4.6(適応的推論)およびGPT-5.2(xhigh)をわずかに下回っています。
GLM-5は、実際の知識労働においてフラッグシップ機に迫る エージェント タスク
アン 1412年のエロ GDPval-AAは、ツールを活用した知識労働タスクにおいて高い相対的勝率を示唆しています。導入の決定においては、多くの生産シナリオが検索、分析、執筆、そしてツールの調整を伴うため、狭いベンチマークにおける静的な精度よりも、この予測精度の方が予測力が高い場合が多いです。
残る違いは、極度の困難と政策の成熟度に現れる
クローズドフラッグシップは、ポリシーの成熟度において優位性を維持することが多い。例えば、より一貫性のある自己チェック、より信頼性の高い拒否境界、そしてエッジケースエラーの減少などが挙げられる。GLM-5はこれらのレベルに近づく可能性はあるが、複雑なタスクの一部については、一貫性のある動作を実現するために、より明確な制約や、より強力なシステムレベルのガードレールが必要となる場合がある。
実際に確認した利点:GLM-5はチャットボットというよりはエンジニアリングの副操縦士のように動作する
より信頼性の高い増分編集、不要な書き換えの削減
周囲の構造を維持しながら局所的な変更が必要な場合、GLM-5はモジュール全体を書き直すのではなく、対象を絞った置換やdiff形式の編集を行うことが多いです。これによりレビューのオーバーヘッドが削減され、回帰リスクの管理が容易になります。
より長いタスクチェーンにおける制約の一貫性の向上
タスクを複数のターンに分割し、前のステップからの厳格な制約を適用すると、GLM-5 はコンテキストが拡大してもそれらの制約の一貫性を保ち、矛盾する仮定を減らす可能性が高くなります。
実行可能なツールチェーン出力の増加と障害後の回復の改善
取得→合成→配信のワークフローでは、モデルが実行可能なステップと明確な「不足している入力」チェックリストを生成できるかどうかに焦点を当てます。GLM-5は、説明レイヤーに留まるのではなく、ワークフローを前進させることが多いです。
事前に知っておくべき制限事項:本番環境への導入を阻むもの
導入とシステムコストは依然として高い
GLM-5はフラッグシップ規模のMoEモデルです。トークンごとにモデルの一部のみがアクティブ化される場合でも、セルフホスティングにはメモリ計画、同時実行スケジューリング、KVキャッシュ戦略、量子化、推論エンジンの互換性など、多大な作業が必要です。
全ての専門分野で自動的に勝利するわけではない
Intelligence IndexとGDPval-AAは、一般的な推論と知識作業のタスクに重点を置いています。ドメインが高度に専門化されている場合(例:厳格なコンプライアンスワークフロー、ニッチな形式的な数学証明、非常にきめ細かいスタイル管理など)、それでもコミットする前に、対象を絞ったA/Bテストを実施する必要があります。
強力なモデルは強力なシステムエンジニアリングに取って代わるものではない
エージェントによるデプロイメントにおいて、最も一般的な失敗は「モデルが応答できない」ことではなく、「実行チェーンが制御されていない」ことです。モデルの機能を安定した本番環境のパフォーマンスにつなげるには、ツールの権限、セキュリティ分離、可観測性、再試行ロジック、そして証拠の検証が不可欠です。
GLM-5を優先する場合
モデルがエンジニアリング ワークフローの重要な部分を担うこと(単に 1 回限りの回答を生成することではない)を目標としている場合、特に次の点において GLM-5 が最有力候補となります。
- 長期コンテキストのエンジニアリングタスク: ファイル間のデバッグ、リファクタリング、複雑な問題のローカリゼーション
- ツール中心のワークフロー: 検索、スクリプト作成、データ合成、文書成果物
- オープンウェイト要件: オンプレミス展開、カスタマイズ、より厳格なコスト/管理境界
ワークロードの大部分が短い Q&A で構成されている場合、コスト/QPS に非常に敏感である場合、またはシステム レベルのガードレールを必要とせず非常に厳格なコンプライアンス境界内で運用している場合は、ベースラインとして軽量モデルまたはクローズド フラッグシップから始めて、明確な利益が得られる場合にのみ GLM-5 を追加することをお勧めします。

